Frédéric Lefebvre-Naré (Isée dataSTRATEGIES) & Mary Le Gardeur (Mix&Match)
La révolution des « big data », celle de l’inflation, du stockage et de l’utilisation des données, pose aux entreprises des défis multiples :
Des leaders, la plupart américains (les GAFA bien sûr, mais aussi Walmart ou Tesla), se sont échappés devant des organisations qui se demandent encore comment avancer. Ce retard s’étend à tous les domaines des entreprises — marketing, finance, RH, production — comme au secteur public.
Qu’est-ce qui freine ? Le manque des bonnes « data personnes » — ou « data scientists », le mot qui s’est imposé depuis 2016 [lien vers indeed] — aux bonnes places.
La demande de salariés dans la data dépassera 2,3 millions d’ici 3 ans aux États-Unis(1), selon une étude initiée par IBM ; le taux de croissance mondial était de l’ordre de + 30%/an ces 5 dernières années (2) ; la data représenterait 8% du PIB en 2020 (3). On s’arrache les « data scientists » au point que 60% des emplois potentiels resteraient non pourvus(4).
Mais le défi pour les entreprises sera surtout de recruter les bons profils de compétences, parmi la diversité de métiers et de formations de « data scientists ».
Car en France, les formations supérieures à la « data » se sont enfin multipliées, surtout depuis 2016. Écoles d’ingénieurs ou d’informatique, écoles de management, universités, toutes les grandes filières de notre enseignement supérieur ont enfin pris en considération la « data ».
Mais à quoi forment-elles ?
Nous avons passé en revue 34 cursus Bac+5 sur le territoire français : quels contenus de formation, pour quels débouchés annoncés ?
Ces débouchés couvrent plus de 30 métiers différents : au-delà du terme « data scientist », des postes de « data » ou « big data engineer » ou « architect », de « data analyst » ou « data analytics consultant », et des métiers existants de l’IT et des SI, bouleversés par le flux des data.
Même diversité dans les contenus de formation : ces 34 cursus enseignent plus de 80 disciplines différentes ; 72 de ces disciplines sont présentes dans au moins 2 cursus.
Un petit nombre de disciplines est commun aux cursus des différentes catégories :
Pour le reste, les contenus sont très contrastés.
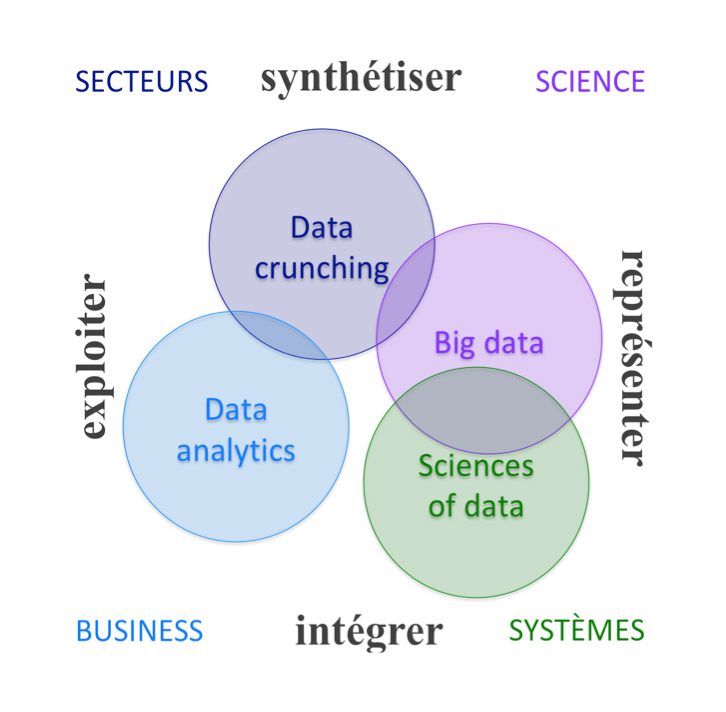
Nous les avons regroupés, par analyse des données (ACP) et clustering, en 4 dominantes que nous avons baptisées « Sciences of Data », « Big Data », « Data Crunching » et « Data Analytics ». Nous tenons l’analyse complète et le positionnement des 34 cursus à disposition, sur simple demande.
Certains cursus sont explicitement dédiés à des applications, par exemple à l’assurance ou aux données biologiques. Leur axe de formation pourrait être nommé « Data Crunching » ou « Data Craft » : il s’agit de produire une connaissance compacte, utilisable par les professionnels d’un métier, à partir de données souvent hétérogènes ou difficiles d’emploi. L’impact des data sur l’humain y est traité à travers l’économie, la « dataviz » ou l’étude des outils de « recommandation ».
Les contenus enseignés : le langage R, les outils big data (bases noSQL, MapReduce, Hadoop, Spark…), les analyses exploratoires dont le clustering, la visualisation des données, le droit et l’éthique des données, et des enseignements spécifiques au secteur, par exemple actuariat ou biostatistiques.
D’autres cursus consistent presque exclusivement en sciences dures : ils pourraient être intitulés « Science of Data ». Le mathématicien Stéphane Mallat vient d’inaugurer au Collège de France un cours de « Sciences des données », Sciences au pluriel. Car plusieurs disciplines concourent à représenter la donnée de façon pertinente et informatiquement efficiente. Ces cursus disent préparer au métier de « data scientist » mais aussi à la recherche, ou au moins à une thèse de doctorat.
Ils associent étroitement des disciplines récentes comme l’apprentissage profond (deep learning), la modélisation des systèmes et la simulation, à des sciences enseignées depuis plusieurs décennies : statistique et probabilités, chaînes de Markov et modèles stochastiques, optimisation et théorie des jeux.
L’empreinte des « big data » sur les systèmes d’information marque un autre type de cursus. Des écoles d’ingénieurs, dont des écoles de Télécoms, le proposent, mais pas seulement elles. Ces cursus forment des « data engineers » ou « data architects », souvent avec le vocabulaire de l’informatique, ses réseaux et ses bases de données. Leurs diplômés sauront gérer la donnée, avec sa granularité individuelle, en temps réel.
Les technologies informatiques sollicitées par les « big data » suffisent en effet à remplir un programme d’enseignement supérieur : cloud computing, informatique distribuée et calcul à haute performance, réseaux et sécurité informatique, capteurs et middleware de l’internet des objets, représentation des connaissances et bases de données, relationnelles comme noSQL, text mining et web sémantique, gestion et traitement de données complexes comme l’image et la vidéo,… Et bien sûr les langages de programmation et outils, le deep learning, plus largement l’intelligence artificielle.
Enfin, un quatrième groupe de cursus forme des « Data Analysts ». C’est l’offre de formation la plus standardisée, car elle s’appuie sur des technologies mûres, déclinées jusqu’à des outils « presse-boutons », dont même le vocabulaire et les conventions se sont imposés sur le marché, comme Google analytics. Ces cursus, proposés essentiellement par des business schools, sont à la fois transversaux et appliqués, car ils portent sur un tronc commun d’applications web, business intelligence, marketing digital… partagé par de nombreux secteurs.
Dans ce tronc commun : les médias sociaux, la culture digitale, les business models et l’économie de la donnée, le marketing basé sur les données. Plus près de l’informatique, le SQL et les bases de données relationnelles, les logiciels SAS ou SPSS, la visualisation des données et les outils de business analytics / business intelligence. S’y ajoutent des formations comportementales caractéristiques des business schools : leadership, communication…
Certains sujets restent peu représentés dans ces cursus, alors que les professionnels les citent fréquemment comme majeurs :
Il y a bien d’autres déficits dans les cursus, puisque beaucoup de sujets aujourd’hui traités par une ou deux des 4 catégories, seraient en fait utiles à tous les professionnels. La data science est souvent définir comme la réunion de trois familles de compétences, « informatiques, statistiques, métier ». Mais dans la réalité, les détenteurs d’une telle palette de compétence sont des aigles à trois pattes !
Chaque personne, chaque formation, chaque poste s’appuient sur des dominantes de compétences qui ne sont qu’une petite partie de l’univers « data ». Les recruteurs, comme les candidats à des emplois dans la data doivent en être conscients pour éviter les désillusions et les mésalliances… ou pour rattraper des carrières mal engagées et frustrantes.
Il appartient bien sûr à chacun d’investir dans les compétences-clé qui rendront faisables ses projets. Il appartient aussi aux professionnels du recrutement de trouver les bonnes personnes pour les bonnes places ! C’est l’objectif que nous nous sommes fixés en créant « Data Mix & Match », le service de recrutement et de placement qui aidera entreprises et professionnels à tirer le meilleur parti de leurs compétences « data » !
© 2018 Mix & Match - Tous droits réservés - Création du site Marguerite Lavayssière